
独家 | 跟源码学数据结构 | 循环队列
- 如果评论区没有及时回复,欢迎来公众号:ByteCode 咨询
- 公众号:ByteCode。致力于分享最新技术原创文章,涉及 Kotlin、Jetpack、算法、译文、系统源码相关的文章
阅读完本文,可以前往 LeetCode 刷
到目前为止不知不觉已经写了三篇关于栈和队列的文章,点击下方链接前去查看。
- 算法动画图解 | 被 “废弃” 的 Java 栈,为什么还在用
- 为什么不推荐使用 Java 栈?为什么现在还有很多人在用?
- 为什么推荐使用
Deque接口替换 Java 栈? - Stack 和 ArrayDeque 区别?
- 栈的时间复杂度?
- 为什么不推荐 ArrayDeque 代替 Stack
- JDK 推荐使用
ArrayDeque代替Stack真的合理吗? - 如何实现一个真正意义上的栈?
- JDK 推荐使用
- 图解 ArrayDeque 比 LinkedList 快
ArrayDeque和LinkedList数据结构的特点?- 为什么
ArrayDeque比LinkedList快?
而今天这篇文章是第 4 篇,主要来学习如何设计循环队列。学习如何设计循环队列之前,我们先来看看 JDK 源码是如何设计的。
通过这篇文章你将学习到以下内容:
- 队列的定义?
- JDK 源码是如何设计队列?
- 队列的大小为什么要设置成 2 的整数次幂?
- 位运算 效率比 非位运算 快多少?
- ArrayDeque 的 2 的整数次幂计算逻辑和 HashMap 有什么区别?
- 自己如何设计一个循环队列?
队列的定义
在开始分析 JDK 源码是如何设计循环队列之前,我们需要先了解队列的基础知识点。
队列是一种 先进先出 的特殊线性表,简称 FIFO,在 Java 中队列有两种形式,单向队列( AbstractQueue ) 和 双端队列( Deque ),单向队列效果如下所示,只能从一端进入,另外一端出去。

双端队列( Deque ), Deque 是双端队列的线性数据结构, 可以在两端进行插入和删除操作,效果如下所示。

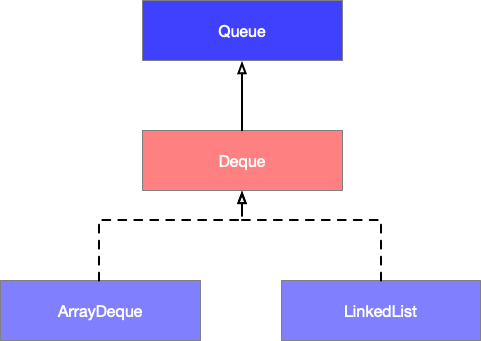
双端队列( Deque )的子类分别是 ArrayDeque 和 LinkedList,ArrayDeque 基于数组实现的双端队列,而 LinkedList 基于双向链表实现的双端队列,它们的继承关系如下图所示。
循环队列
循环队列是一种线性数据结构,将队尾连接在队首,形成一个环,而 Java 中 ArrayDeque 是基于数组实现的循环队列,而 LinkedList 属于链式队列。
更多关于
ArrayDeque和LinkedList的优缺点,在什么情况下使用,以及它们谁更快,请前往查看 图解 ArrayDeque 比 LinkedList 快
ArrayDeque 和 LinkedList 数据结构的特点如下所示:
| 集合类型 | 数据结构 | 初始化及扩容 | 插入/删除时间复杂度 | 查询时间复杂度 | 是否是线程安全 |
|---|---|---|---|---|---|
| ArrqyDeque | 循环数组 | 初始化:16 扩容:2 倍 |
0(n) | 0(1) | 否 |
| LinkedList | 双向链表 | 无 | 0(1) | 0(n) | 否 |
在上一篇文章 图解 ArrayDeque 比 LinkedList 快 从速度和内存两个方面分析了 ArrayDeque 的性能都比 LinkedList 要好,并结合实际的案例来验证,结果如下图所示。

ArrayDeque 源码分析
本文的目的主要来分析循环队列,我们先来看一下 JDK 源码是如何基于数组的形式实现的双端队列,ArrayDeque 继承关系如下图所示。
接口 Deque 和 Queue 提供了两套 API ,存在两种形式,分别为抛出异常,和不抛出异常,返回一个特殊值 null 或者布尔值 ( true | false )。
| 操作类型 | 抛出异常 | 返回特殊值 |
|---|---|---|
| 插入 | addXXX(e) | offerXXX(e) |
| 移除 | removeXXX() | pollXXX() |
| 查找 | element() | peekXXX() |
成员变量分析
ArrayDeque 内部有四个变量: 数组 elements 、 头指针 head 、 尾指针 tail 、 最小初始化容量 MIN_INITIAL_CAPACITY
// 数组的长度,总是 2 的整数次幂 |
构造方法分析
构造方法分别有 有参构造方法 和 无参构造方法,这里我们主要关注点在 2 的整数次幂计算逻辑。
// 无参构造方法,直接初始化容量为 16 的数组 |
- 无参构造方法(默认),直接初始化容量为 16 的数组
- 有参构造方法,会初始化最接近 2 的整数次幂的大小的数组。而
allocateElements(numElements)方法的返回值是最接近 2 的整数次幂
为什么要设置成 2 的整数次幂
任何一个数 和 2^n-1 做与运算,保证指针 head 的索引和尾指针 tail 的索引,落在队列范围内。一个正数 x 和 2^n-1 做与运算,结果如下所示。
例如 2^n-1 = 16 |
而一个负数 x 和 2^n-1 做与运算,结果如下所示。
例如 2^n-1 = 16 |
注意:
ArrayDeque 的 2 的整数次幂计算逻辑,相比于 HashMap 的计算逻辑是有一点区别的,如下图所示。

HashMap 的 2 的整数次幂计算逻辑,在进行位运算之前先执行了 cap - 1 的操作,而 ArrayDeque 没有,这么做的区别在于,假设传进去来的是 8 正好是 2 的整数次幂, ArrayDeque 计算出来的结果是 16,而 HashMap 的计算结果是其本身 8 ,这么做的目的,是为了省内存。
元素入队分析
无论是通过 add(e) 或者 offer(e) 方法将元素插入到队列中。最终都是调用 addLast(E e) 方法。
...... |
上述代码中,实现循环队列,最核心的就是下面这句。
(tail = (tail + 1) & (elements.length - 1)) == head |
- 重新计算 tail 的索引指向的下一个位置
- 判断队列是否已满,如果已满执行
doubleCapacity()方法进行扩容
通过以下方法判断队列是否为空。
public boolean isEmpty() { |
如果头指针 head 的索引和尾指针 tail 索引相同,即当前队列为空。
元素出队分析
无论是通过 add(e) 或者 offer(e) 方法将元素从队列中删除。最终都是调用 pollFirst() 方法。
public E pollFirst() { |
到这里关于 ArrayDeque 源码最核心的部分分析完了,其中最重要的核心算法,是通过任何一个数 x 和 2^n-1 做与运算,来保证头指针 head 的索引和尾指针 tail 的索引,落在队列范围内。
JDK 之所以这么做是为了提高程序的执行效率,接下来我们通过一个案例来验证 位运算 和 非位运算 它们的执行效率。
设计循环队列
因为篇幅原因,本文只演示一种语言,更多语言的实现,前往查看 设计循环队列
题目来源于 LeetCode 上第 622 号问题:设计循环队列。题目难度为 Medium。
- 英文地址:https://leetcode.com/problems/design-circular-queue
- 中文地址:https://leetcode-cn.com/problems/design-circular-queue
题目描述
设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
你的实现应该支持如下操作:
- MyCircularQueue(k): 构造器,设置队列长度为 k 。
- Front: 从队首获取元素。如果队列为空,返回 -1 。
- Rear: 获取队尾元素。如果队列为空,返回 -1 。
- enQueue(value): 向循环队列插入一个元素。如果成功插入则返回真。
- deQueue(): 从循环队列中删除一个元素。如果成功删除则返回真。
- isEmpty(): 检查循环队列是否为空。
- isFull(): 检查循环队列是否已满。
示例:
MyCircularQueue circularQueue = new MyCircularQueue(3); // 设置长度为 3 |
提示:
- 所有的值都在 0 至 1000 的范围内
- 操作数将在 1 至 1000 的范围内
- 请不要使用内置的队列库
方法一:位运算
参数的含义:
data:表示固定的数组,用作循环队列,而队列的长度是最接近于 2 的整数次幂allocateElements():用于计算队列的大小,返回值是最接近 2 的整数次幂head:表示的队列的头指针索引tail:表示队列的尾指针索引count:表示队列中的元素数量size:表示队列中最多可以容纳的元素数量
判断队列是否已满
((tail + 1) & (data.length - 1)) == head || (count >= size) |
- 任何一个数 和
2^n-1做与运算,保证头指针head和尾指针tail的索引,都落在队列范围内 - 队列的长度是最接近于 2 的整数次幂,会大于实际的队列大小,所以需要变量
count统计当前队列中的元素数量,如果count >= size表示队列已满
判断队列是否为空
head == tail |
复杂度分析:
- 时间复杂度:O(1) ,数组存储都是按顺序存放的,具有随机访问的特点
- 空间复杂度:O(N) ,N 为数组的长度
代码实现:
class MyCircularQueue { |
方法二: 非位运算
参数的含义:
data:表示固定的数组,用作循环队列head:表示的队列的头指针tail:表示队列的尾指针
判断队列是否已满
(tail + 1) % size == head |
判断队列是否为空
head == tail |
复杂度分析:
- 时间复杂度:O(1) ,数组存储都是按顺序存放的,具有随机访问的特点
- 空间复杂度:O(N),N 为数组的长度
代码实现
class MyCircularQueue { |
位运算 和 非位运算 执行效率对比。

很明显 位运算 效率远远高于 非位运算,数据量越大,差距会越来越大,并且我在测试过程中,通过 位运算 的方式提交, 在 Java 提交中打败了 100% 的用户。
如果有帮助 点个赞 就是对我最大的鼓励
代码不止,文章不停
欢迎关注公众号:ByteCode,持续分享最新的技术
最后推荐长期更新和维护的项目:
个人博客,将所有文章进行分类,欢迎前去查看 https://hi-dhl.com
KtKit 小巧而实用,用 Kotlin 语言编写的工具库,欢迎前去查看 KtKit
计划建立一个最全、最新的 AndroidX Jetpack 相关组件的实战项目 以及 相关组件原理分析文章,正在逐渐增加 Jetpack 新成员,仓库持续更新,欢迎前去查看 AndroidX-Jetpack-Practice
LeetCode / 剑指 offer / 国内外大厂面试题 / 多线程 题解,语言 Java 和 kotlin,包含多种解法、解题思路、时间复杂度、空间复杂度分析
近期必读热门文章
- 图解 ArrayDeque 比 LinkedList 快
- 为什么不推荐 ArrayDeque 代替 Stack
- 算法动画图解 | 被 “废弃” 的 Java 栈,为什么还在用
- 影响性能的 Kotlin 代码(一)
- Jetpack Splashscreen 解析 | 助力新生代 IT 农民工 事半功倍
- 为数不多的人知道的 Kotlin 技巧及解析(三)
- 为数不多的人知道的 Kotlin 技巧以及 原理解析(二)
- 为数不多的人知道的 Kotlin 技巧以及 原理解析(一)
- 揭秘 Kotlin 中的 == 和 ===
- Kotlin 密封类进化了
- Kotlin 中的密封类 优于 带标签的类
- Kotlin Sealed 是什么?为什么 Google 都在用
- Android 12 行为变更,对应用产生的影响
- 图解多平台 AndroidStudio 技巧(三)
- Kotlin StateFlow 搜索功能的实践 DB + NetWork
- Kotlin 插件的落幕,ViewBinding 的崛起
- 本文作者:hi-dhl
- 本文标题:独家 | 跟源码学数据结构 | 循环队列
- 本文链接:https://hi-dhl.com/2021/10/14/algorithm/04-loop-queue/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 hi-dhl
