
迭代器 Iterable 这么慢吗?而它让性能提升 N 倍
- 如果评论区没有及时回复,欢迎来公众号:ByteCode 咨询
- 公众号:ByteCode。致力于分享最新技术原创文章,涉及 Kotlin、Jetpack、算法、译文、系统源码相关的文章
视频版 bilibili地址: b23.tv/cumiLVf
关于 Sequence 我在之前的两篇文章都介绍过,无论在执行速度和内存方面 Sequence 的性能都比 Iterable 好,有兴趣的朋友可以去看一下:
在上一篇文章中测试了反射的性能 揭秘反射真的很耗时吗,射10万次用时多久,这篇文章我们一起来分析一下 Sequence 和 Iterable 的性能和执行过程。
这期内容分为 视频版 和文字版,仅仅靠文字无法很好的描述它们的执行过程,视频版以动画的形式描述了 Sequence 和 Iterable 的执行过程和性能测试过程,欢迎前往查看。
视频版 bilibili地址: b23.tv/cumiLVf
这期内容将会从 速度 和 内存 两方面测试一下它们之间的差距。我们先来看一看 Sequences 和 Iterable 数据结构,它们的数据结构非常的相似。
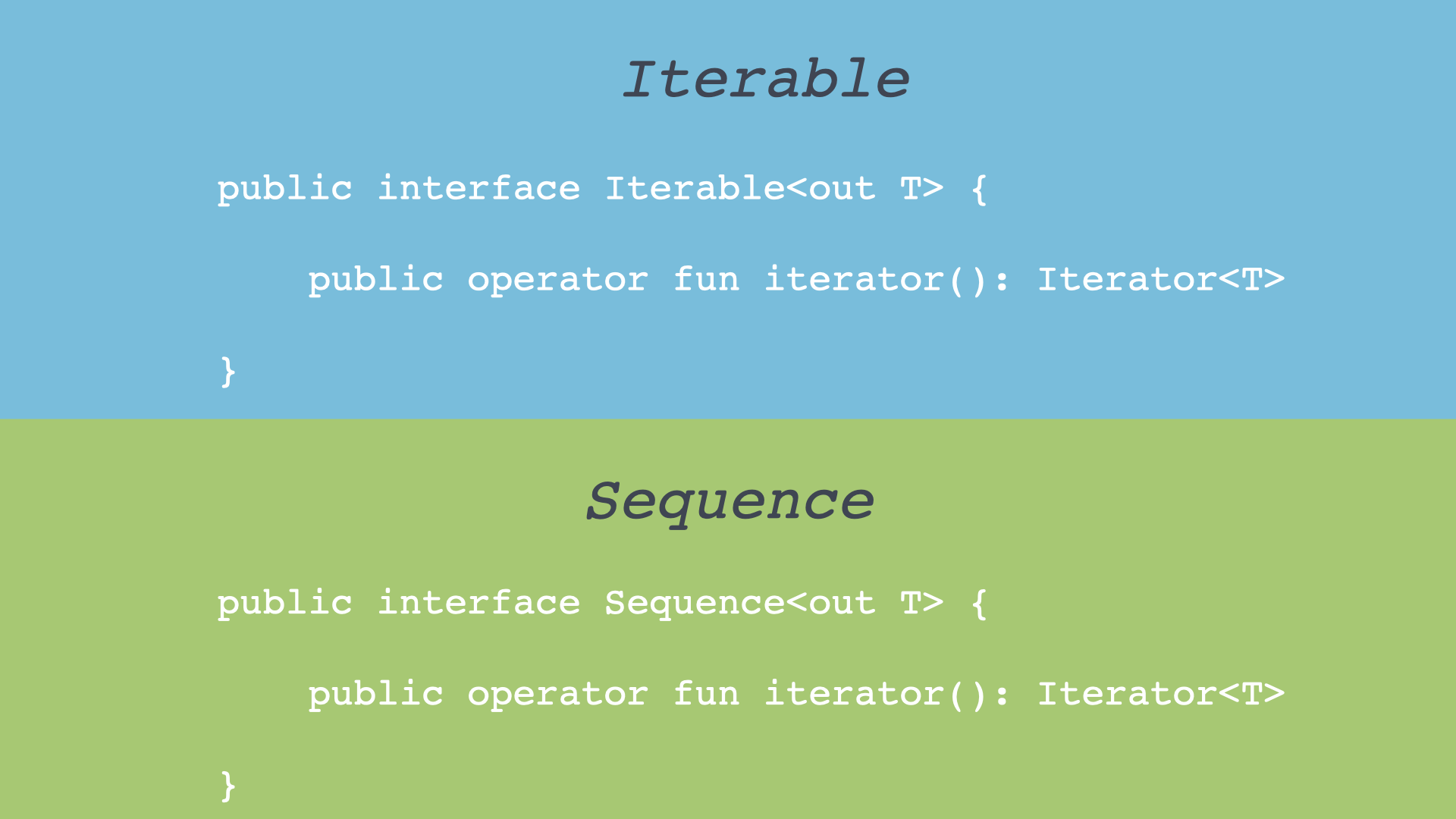
Sequences 和 Iterable 虽然结构很相似,但是他们的性能缺相差很大,在开始测试之前,我们先来看看它们的执行过程。
Iterable 的执行过程
Iterable 会立即处理输入的元素,在处理过程中,每遇到一个操作符,都会创建一个新的数组列表,将结果保存到新的数组列表中,之后在传递给下一个操作符,以此类推,直到操作符结束,我们来看一段代码。
(1..3).asIterable() |
Iterable 执行过程如下图所示。

- 初始集合所有元素
1, 2, 3,遇到第一个操作符map,会创建一个新的数组列表,遍历初始集合所有元素,每个元素 x 2 保存到新的数组列表中,输出2, 4, 6,源码如下所示
// 每次操作都会开辟一块新的空间,创建一个新的数组列表 ArrayList,存储计算的结果 |
- 然后调用第二个操作符
filter,会再次创建一个新的数组列表,遍历集合中所有元素,将大于 2 的元素,保存到新的数组列表中,输出4, 6,源码如下所示
// 每次操作都会开辟一块新的空间,创建一个新的数组列表 ArrayList,存储计算的结果 |
如果每次调用操作符 map 、 filter 时,都创建一个新的数组列表,将结果保存到新的数组列表中。这么做存在性能问题。
1. 浪费内存
每次调用操作符 map 、 filter 时,都需要临时申请一段内存存储中间结果。
如果每次操作都需要申请内存,存储中间结果,这是对内存极大的浪费,因为我们只关心最后的结果,而不是中间的过程。
2. 执行速度慢
每次调用操作符 map 、 filter 时,都会生成一个 while{...} 循环, 原本只需要遍历一次就能做完的事,被拆分多个循环来完成,如果在大量数据的情况下,这个速度是很糟糕的。
Sequences 的执行过程
Sequence 用来表示一个延迟计算的集合,每次遇到一个中间操作符都不会执行,会把它添加到待执行的操作列表中,构成一个待执行的调用链,直到遇到终端操作符( toList 、 count 、 forEach 等等)才会开始执行。
我们可以通过 asSequence 扩展函数,将现有的集合转换为 Sequence ,示例代码如下所示。
(1..3).asSequence() |
Sequence 执行过程如下图所示。

- 初始集合所有元素
1,2,3,调用asSequence扩展函数,将现有的集合转换为Sequence - 遇到第一个操作符
map,map是中间操作符,不会执行,会把它添加到待执行的操作列表中 - 然后调用第二个操作符
filter,filter也是一个中间操作符,也会把它添加到待执行的操作列表中。 - 调用最后一个操作符
forEach,forEach是终端操作符,遇到终端操作符时,会触发中间操作符的执行,初始集合每个元素都会执行一遍map -> filter -> forEach,直到所有元素处理完毕
在 Sequences 处理过程中,遇到中间操作符 map 、 filter 不会执行,只是构建了一个待执行的调用链,只有遇到末端操作符 forEach 才开始处理元素,这么做有以下好处:
- 速度更快,将多个中间操作符,构成一个待执行的调用链,集合中每个元素在调用链上传递,避免了很多无用操作,提升了整体速度
- 占用更少的内存,在执行过程中,不会创建新的列表存储中间结果,因此它占用的内存更少
如何区分末端操作符还是中间操作符
看方法的返回类型,如果返回的是 Sequence 表示是中间操作符,否则是终端操作符,源码如下所示。
// 中间操作 map ,返回的是 Sequence |
如果是中间操作 map 、 filter ,它们返回的是一个 Sequence,末端操作返回的是一个具体的类型 List 、 Int 、 Unit 等等,源码如下所示。
// 末端操作 count, 返回的是 Int |
如果是末端操作符 toList 、 count 、 forEach 等等,返回的是一个具体的类型 List 、 Int 、 Unit。
了解完 Sequences 和 Iterable 的执行过程,接下里我们实操一下,通过 JMH 工具测试一下它们的执行速度,通过 jcmd 生成 hprof 文件查看它们的总内存。
JMH (Java Microbenchmark Harness),这是 Oracle 开发的一个基准测试工具,因为 JVM 会对代码做各种优化,而 JMH 会尽可能的减少这些优化对最终结果的影响,尽可能的保证结果的可靠性。
代码已经上传到 Github 仓库 KtPractice 欢迎前往查看,运行 SequenceBenchmark 和 TestSequenceMemory 即可生成结果。
Github 仓库 KtPractice 地址:
https://github.com/hi-dhl/KtPractice
Sequences 和 Iterable 执行速度对比
在开始测试之前,我们需要先设计测试方案:
- 在单进程,10 个线程中,分别对
Sequences和Iterable执行 10 轮测试,每轮遍历 10 万条数据,取平均值 - 在执行之前,需要对代码进行预热,预热不会作为最终结果,预热的目的是为了构造一个相对稳定的环境,保证结果的可靠性。因为 JVM 会对执行频繁的代码,尝试编译为机器码,从而提高执行速度。而预热不仅包含编译为机器码,还包含 JVM 各种优化算法,尽量减少 JVM 的优化,构造一个相对稳定的环境,降低对结果造成的影响。
- JMH 提供 Blackhole,通过 Blackhole 的 consume 来避免 JIT 带来的优化
现在分别使用 Sequences 和 Iterable 调用它们各自的 filter 、 map 方法,处理相同数据的情况下,比较它们的执行时间。
Iterable
@Benchmark |
处理完 10 万条数据之后,10 轮测试平均耗时 10.259 ms/op 。
Sequences
@Benchmark |
经过长时间运行之后,10 轮测试平均耗时 4.914 ms/op,这个结果很让人吃惊,Sequences 比 Iterable 快 6 倍。如下图所示:
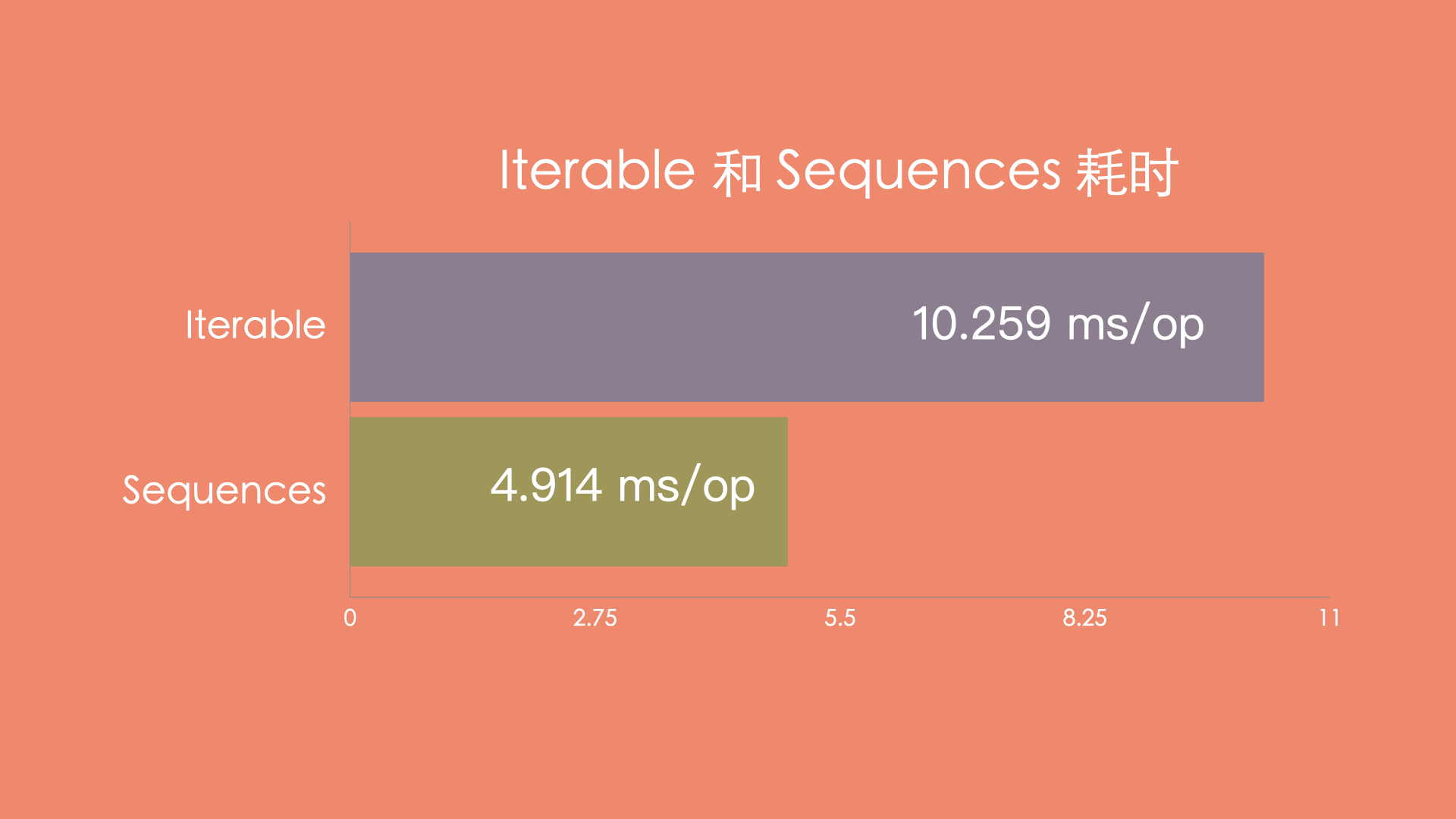
在实际情况中,集合里面保存的元素更加复杂,因此占用内存、和执行速度之间的差距也会越来越大。尤其在处理大数据的时候,效果是更加明显的,数据量越大,它们的时间差距会越来越大。
Sequences 和 Iterable 内存对比
在开始测试之前,我们需要先设计测试方案:
- 分别使用
Sequences和Iterable,创建 10 万个对象,查看当前内存情况 - 利用 JDK 提供的工具
jcmd在循环结束后,方法结束前,生成hprof文件,查看当前总内存大小 - 需要一个简单的测试类,作为
Sequences和Iterable测试数据,测试类如下所示
data class Model(val no: Int) { |
现在分别使用 Sequences 和 Iterable 调用它们各自的 filter 、 map 方法,来看看它们的内存占用情况。
Iterable
(1..100_000).asIterable() |
创建 10 万个对象之后,在方法执行结束前,生成 hprof 文件,分析之后,总共占用 6 MB (6, 046, 244 byte) 内存。
Sequences
(1..100_000).asSequence() |
总共占用 1 MB (1, 495, 413 byte) 内存,最终 Sequences 和 Iterable 内存占用情况如下所示。
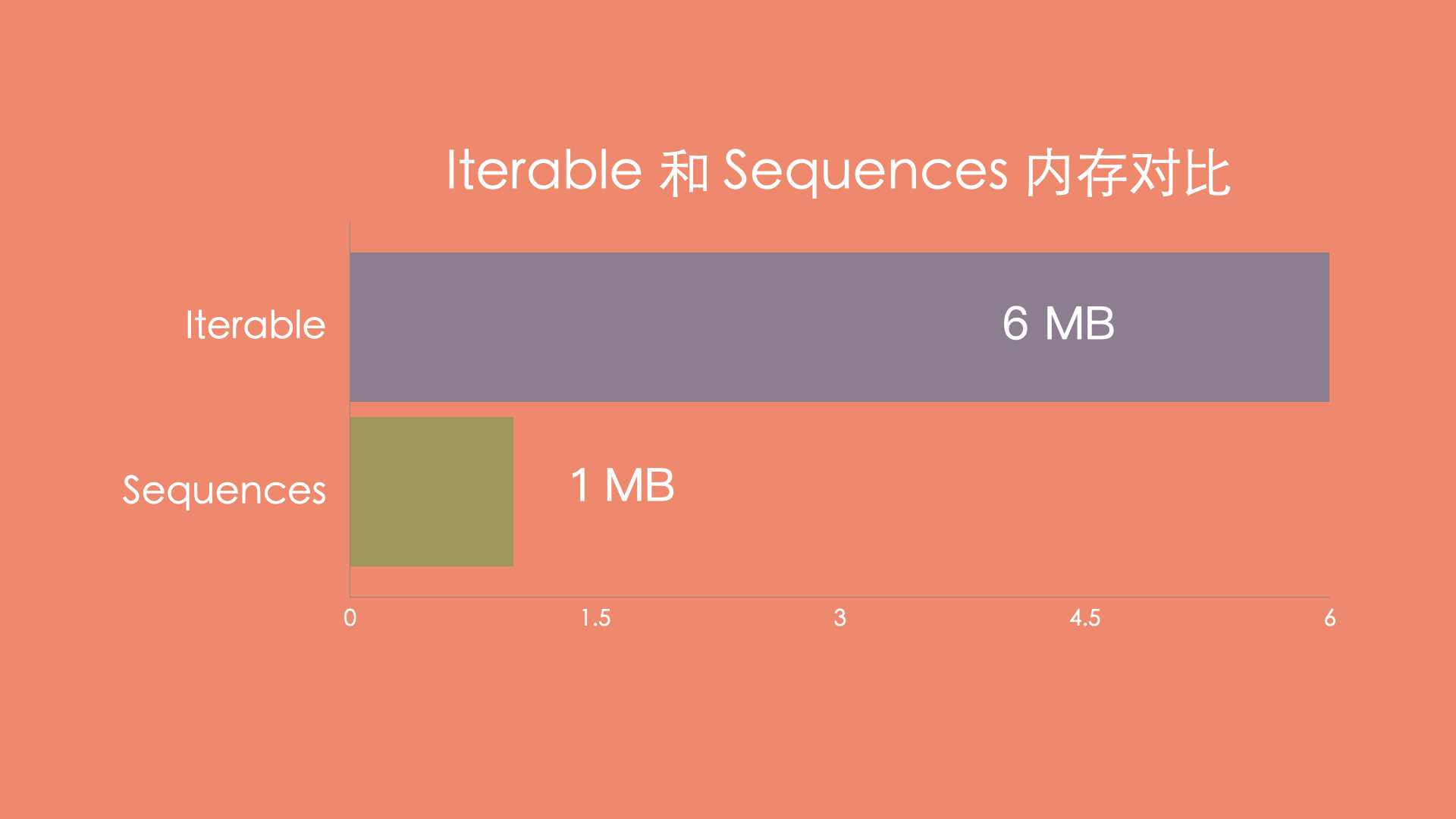
这个结果非常的惊人, Iterable 占用的内存是 Sequences 6 倍,这是因为 Iterable 每次遇到一个操作符,都会创建一个新的数组列表,将结果保存到新的数组列表中,导致了浪费更多的内存
Iterable 和 Sequences 如何选择
经过速度和内存测试,我们知道了使用 Sequences 不仅可以提高速度,而且占用的内存更少。那么如何选择 Iterable 和 Sequences。
- 如果包含多个操作符,建议选择
Sequences - 在数据量很小的情况下,选择任意一个都可以,但是如果是在递归当中使用,无论数据大小,建议优先考虑
Sequences - 如果处理的数据量比较大,
Sequence是最好的选择,因为不会创建新的数组列表,内存开销更小,而且速度更快 - 如果单个 Model 非常的复杂,无论数据集大小,建议优先考虑
Sequences,如果无法确定,那么在想使用Iterable的时候,优先考虑Sequences
本文代码已经全部上传到 Github 仓库 KtPractice 欢迎前往查看,运行 SequenceBenchmark 和 TestSequenceMemory 即可生成结果,或者进入仓库 report/sequence 目录下查我已经生成好的结果。
Github 仓库 KtPractice 地址:
https://github.com/hi-dhl/KtPractice
全文到这里就结束了,感谢你的阅读,如果有帮助,欢迎 在看 、 点赞 、 收藏 、 分享 给身边的朋友。
真诚推荐你关注我,公众号:ByteCode ,持续分享硬核原创内容,Kotlin、Jetpack、性能优化、系统源码、算法及数据结构、动画、大厂面经。
近期必读热门文章:
- 揭秘反射真的很耗时吗,射10万次用时多久
- 揭秘 Kotlin 1.6.20 重磅功能 Context Receivers
- Stack Overflow 上最热门的 10 个 Kotlin 问题
- Android 12 已来,你的 App 崩溃了吗?
- Google 宣布废弃 LiveData.observe 方法
- 影响性能的 Kotlin 代码(一)
- 为数不多的人知道的 Kotlin 技巧及解析(三)
- 揭秘 Kotlin 中的 == 和 ===
最后推荐长期更新和维护的项目:
个人博客,将所有文章进行分类,欢迎前去查看 https://hi-dhl.com
KtKit 小巧而实用,用 Kotlin 语言编写的工具库,欢迎前去查看 KtKit
计划建立一个最全、最新的 AndroidX Jetpack 相关组件的实战项目以及相关组件原理分析文章,正在逐渐增加 Jetpack 新成员,仓库持续更新,欢迎前去查看 AndroidX-Jetpack-Practice
LeetCode / 剑指 offer / 国内外大厂面试题 / 多线程题解,语言 Java 和 kotlin,包含多种解法、解题思路、时间复杂度、空间复杂度分析
- 本文作者:hi-dhl
- 本文标题:迭代器 Iterable 这么慢吗?而它让性能提升 N 倍
- 本文链接:https://hi-dhl.com/2022/05/20/kotlin/22-iterable-Sequence/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 hi-dhl
